I had an interesting debugging challenge recently, investigating strange latencies in several services. One symptom I observed had outgoing requests taking one second longer than usual. Why one second?
There didn’t seem to be anything in our applications themselves which would cause this. No suspicious timeouts, retries, locks or weird sleeps.
Google didn’t help much, including searching for variations on:
- one second timeout
- 1000 millisecond timeout
- single second delay
- 1000ms network latency
After giving up and moving on, I recently found another instance of this strange phenomenon! Luckily, a colleague offered an explanation for one second latencies: SYN retransmission.
SYN retransmission
SYN packets are the first packet sent as part of the TCP three-way handshake. The Linux kernel has a default timeout of one second after which it will retry by sending another SYN packet.
Mystery solved!
Well, partly. The question still remains: why was it taking so long to get a SYN ACK back? I don’t know yet.
Listening TCP sockets have a SYN queue. SYN packets wait here until an ACK comes back from the client to complete the three-way handshake. There an also an Accept queue, where initiated connections wait to be accepted by the application.
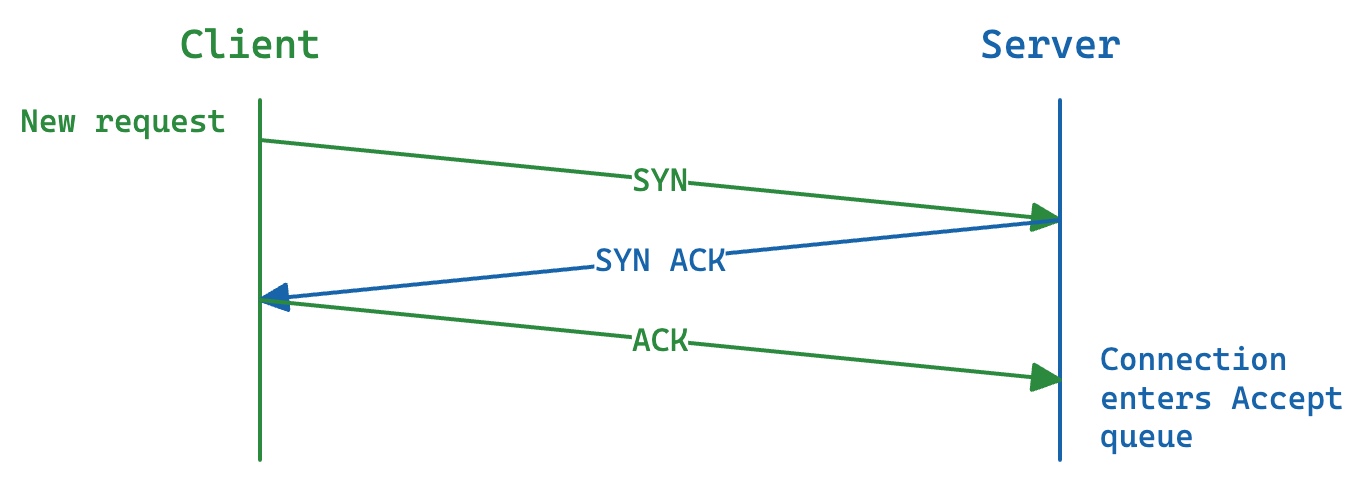
TCP handshake
If the Accept queue fills up, new incoming SYNs and ACKs will be dropped. If the SYN queue fills up, SYN Cookies can be used (and are enabled by default in the kernel).
Given that, some possible explanations include:
- The SYN queue on the remote host was full. In which case either we might expect to see SYN Cookies being used, unless the remote isn’t using SYN Cookies.
- The Accept queue on the remote was full.
- Something in the network was slow, and delayed either the outgoing SYN or incoming SYN ACK. In which case, we’d expect to see similar delays for other packets too.
- Something in the network was dropping packets. Again, we’d expect to see correlated packet loss across all packet types.
- Something else I haven’t considered.
I don’t think it was 1, because we didn’t see any SYN Cookies. We did see some strange delays in other incoming and outgoing packets, so currently I’m thinking 3 is most likely, but that just raises more questions. 2 could be possible, but in some cases we’re connecting to Cloudflare and I’m pretty sure they can handle this amount of traffic.
So there’s still a mystery there.
Unexpected RSTs
That wasn’t the only mystery though. While analysing a packet capture, I did find something else interesting: we were making way more connections than we should have been. The application was supposed to be using a TCP connection pool, but after (almost) every request the connection was being closed by our app with a RST.
For most requests this application doesn’t care about response bodies. It does a POST to create a thing, checks the status is a 2xx and ignores the rest of the response. However, when hyper sees that the HTTP response body hasn’t been consumed, instead of returning the connection to the pool it will shut down the connection. If this body data (well, any data) is still in the TCP receive buffer, then the socket will send a RST instead of a FIN. Today I learned.
To me, what hyper does here seems a bit like a restaurant throwing away the whole plate whenever a customer doesn’t finish their meal. Instead they could, you know, get rid of the leftovers and clean the plate, ready for the next person? Throwing away the whole plate is just wasteful. There are probably good reasons for this behaviour, but I found it surprising.
A note on connection pooling
TCP connection reuse isn’t without its own potential problems. Race conditions can happen when it’s not clear who should close the connection and when. For example, imagine the client and server both have a timeout after which they will close the connection. If the client sends a new request just before the timeout fires, but the server receives the request after its own timeout fires, then we have a problem.
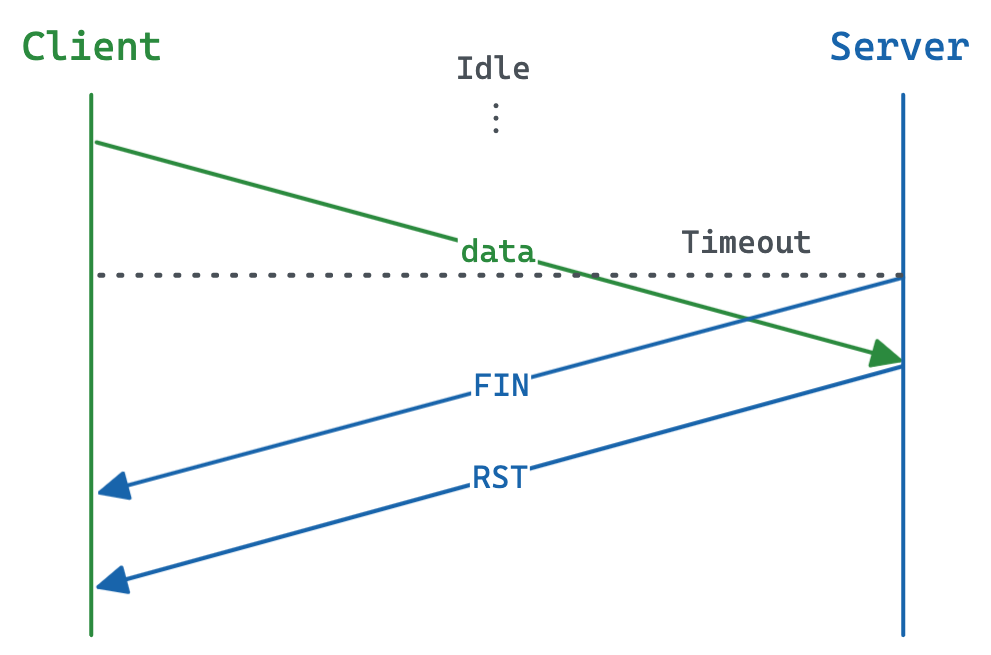
TCP race condition
We can mitigate this by setting the server’s timeout to a suitably higher value than the client’s (often double), but this becomes harder when you don’t control both!
Failing that, for idempotent requests we can detect these connection resets and retry. I’ve written about retries before, and while I generally recommend keeping retries at the entrypoint of a system, a quick retry after a RST can work quite well.