Context
Some write operations depend on the result of a previous read. Concurrent requests might cause the write to fail or update state incorrectly. Atomic transactions aren’t always enough to prevent these issues (depending on the isolation level).
Examples
Creating a post in a social network. A new post should only be created once. Retries should succeed but not create duplicate posts. Imagine two concurrent requests try to create the post. First, both reads might see no post already exists. Then there are two possible error cases: both writes succeed and two posts are created, or one write fails with a uniqueness error.
An app which aggregates a user’s bank account data. When refreshing the account data, each account should be updated if it already exists in the database, otherwise a new row should be inserted. Concurrent refreshes could cause the same problem as above.
Debiting an account balance. This needs to read the current balance, add the amount being debited, then write the result. Concurrent requests could cause a lost update, resulting in one of the debits being overwritten and money being lost.
Optimistic concurrency. Each row in a table has an integer version column, which gets incremented on every update. Clients fetch a version, say 1, make some changes then try to write a new version, 2 in this case. Clients send the current version (1) along with the update request. The application checks that this version matches the version in the database. If they don’t match, the update should be rejected. Race conditions can occur, as illustrated below.
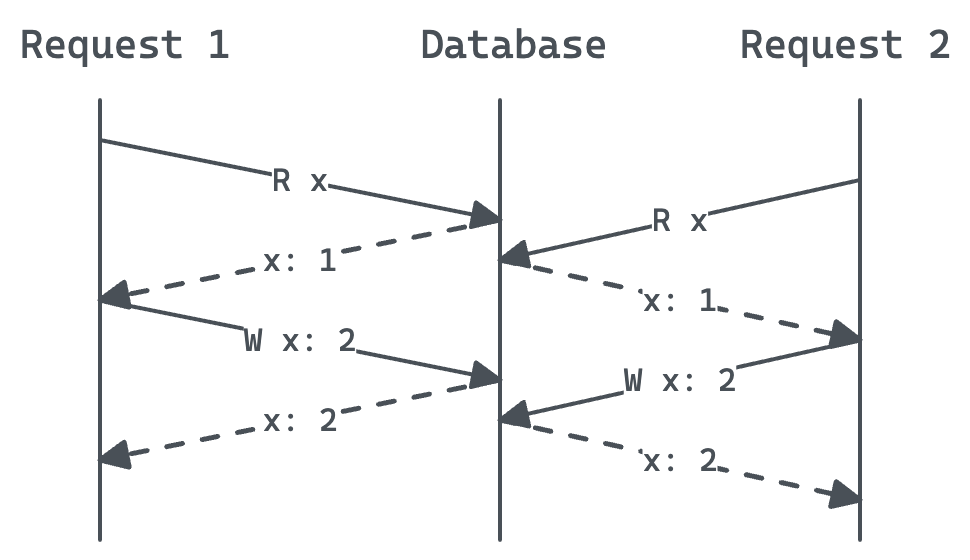
Optimistic concurrency: race condition. Both requests read x, see version 1, and write version 2. The second overwrites the first.
Problem
How do we prevent problems caused by concurrent read-then-writes?
Solution
Do the read-then-write operation atomically. There are various techniques available, including:
- Using atomic (linear) database operations, such as the following for PostgreSQL. Check your database documentation for equivalents and atomicity guarantees.
ON CONFLICT DO NOTHINGfor unique atomic inserts andON CONFLICT DO UPDATEfor atomic upserts. Use a unique ID associated with the request. This could be a client-supplied ID for the resource, but often this isn’t desirable so an idempotency key could be used instead. Insert this ID into a unique column in the same table as the resource data. No duplicate records will be created, and the operation will succeed when retried.UPDATE table SET balance = balance + $1for atomic updates based on current state.
- Using locks to prevent concurrent operations on the same data. There are many forms of locking, including
SELECT FOR UPDATEin SQL to lock a row for later updating. More coarse-grained locks can also be used, e.g. an idempotency key lock around the whole operation. - Using strict transaction isolation levels to prevent phenomena such as the lost update described above. However, be aware that some levels might also cause increased transaction failures.
Read-then-write isn’t the only problematic access pattern to watch out for. See The Zoo of Transaction Phenomena for more.
Example: optimistic concurrency
Using this pattern, one of the two requests in the optimistic concurrency example above will fail.
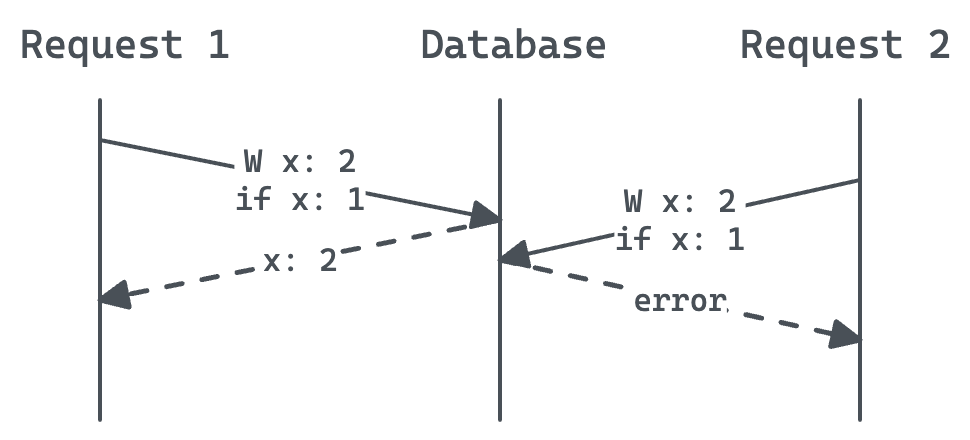
Optimistic concurrency: fixed using atomic read-then-write operations.
Using PostgreSQL, it’s possible to implement this pattern with INSERT ... ON CONFLICT and conditional updates.
-- Insert first version - only inserts if no row exists for ID 123
INSERT INTO my_versioned_data AS d (id, my_data, version)
VALUES ('an_id', 'original', 1)
ON CONFLICT DO NOTHING
RETURNING id;
-- Returns 1 row if new, 0 rows if it already exists
-- Some time later, someone wants to make an update:
-- Fetch my_data to modify
SELECT my_data, version FROM my_versioned_data WHERE id = 123;
-- returns version 1
-- Update to version 2 - only updates if version is still 1
UPDATE my_versioned_data AS d
SET my_data = 'updated', version = 2
WHERE id = 'an_id' AND version = 1
RETURNING id;
-- Returns 1 row if the version matches and the update succeeds, else 0 rows
Another neat trick, if we want to insert some data only if it doesn’t already exist, and always return the row, is to do a fake update.
INSERT INTO my_versioned_data AS d (id, my_data, version)
VALUES ('an_id', 'attempted_insert', 1)
-- We need to (fake) update something to return values
-- if the row already exists
ON CONFLICT (id) DO UPDATE
SET id = 'an_id'
RETURNING id, my_data, version;
-- Returns 1 row always, with the current my_data and version
See also
- Atomicity (database systems)
- Isolation (database systems)
- Linearizability
- Consistency Models
- Practical Guide to SQL Transaction Isolation
- Transaction isolation in PostgreSQL
- PostgreSQL anti-patterns: read-modify-write cycles
- The Zoo of Transaction Phenomena
Related
- ACID transaction – Perform multiple writes, such that either all of them or none of them succeed
- Idempotency key lock – Protect against concurrent retries
- Idempotency key – Identify identical requests